
OpenRouter vs LiteLLM: Which LLM Gateway Should You Choose in 2026?
OpenRouter vs LiteLLM compared on pricing, deployment, performance, and governance. Pick the right LLM gateway based on your stack and production needs.

Sohrab Hosseini
Co-founder (Orq.ai)

Bring LLM-powered apps from prototype to production
Discover a collaborative platform where teams work side-by-side to deliver LLM apps safely.







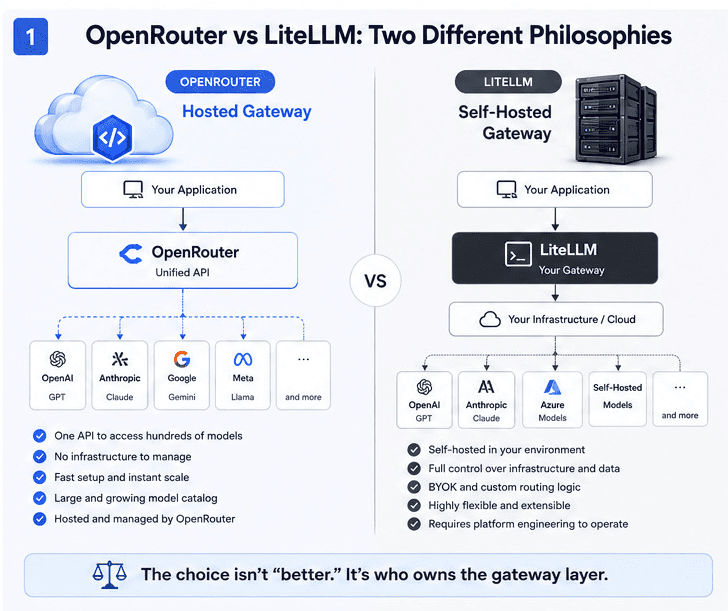
Choosing an LLM gateway used to be easy.
Pick one vendor, wire up their SDK, then call it a day.
In 2026, that’s hardly enough. We see teams juggling several models and providers while trying to find a cleaner way to manage cost traffic instead of just sprinkling a few API keys around the codebase. That’s usually when OpenRouter and LiteLLM show up in the same evaluation doc.
Both promise one interface to many models, but they make very different trade-offs in how they do it.
ro
This guide is for the people stuck in the middle of that decision: platform teams, infra‑minded product engineers, and AI leads who need something that will survive real production traffic, not just demos.
The goal isn’t to crown a universal winner, but to be explicit about what each tool is good at, where it falls short, and what you’re signing up to operate if you adopt it.
We’ll look at OpenRouter and LiteLLM side by side on the dimensions that matter in practice. Things like model coverage, routing, performance, and pricing. Then, we'll discuss when a managed gateway or router might be a better fit than either.
At a glance: comparison table
To get a better idea of how OpenRouter and LiteLLM stack up against each other, take a look at the table below:
Dimension | OpenRouter | LiteLLM |
Type | Hosted multi‑provider LLM gateway with one public API | Open‑source LLM proxy / SDK you run yourself (optional hosted add‑ons) |
Number of Models | Hundreds of chat/embedding models exposed through a unified catalog | Hundreds of models, depending on which providers you connect and enable |
Number of Providers | Dozens of commercial and open‑source providers via a single endpoint | Any providers you configure (OpenAI, Anthropic, Azure, self‑hosted, etc.) |
Pricing | Pay‑per‑token on top of provider pricing; free tier plus paid usage plans | Core project is free; you pay providers directly and for any infra you run |
Deployment Model | Fully hosted, managed by OpenRouter | Self‑hosted in your own cloud or infra; some teams layer services on top |
Latency Overhead | Extra network hop through their gateway; no infra to operate yourself | Depends on your deployment and network; you control hops and proximity |
License | Closed‑source SaaS | Open‑source (permissive license) with commercial options around it |
Best for | Teams that want a quick, hosted way to hit many models from one API | Teams that want maximum control and are comfortable running their own gateway logic |
What is OpenRouter?
OpenRouter is a hosted LLM gateway that gives you one public API to reach many different models and providers. Instead of wiring your apps directly to individual vendors, you point them at OpenRouter’s endpoint and select models by ID. OpenRouter handles authentication and routing to each upstream while returning responses in a consistent format. It’s very much “multi-provider access as a service,” instead of something you run yourself.
Provider and model coverage
Put simply, OpenRouter focuses on breadth. A large catalog of models from multiple commercial and open-source providers, all exposed behind a single interface.
What that means is you can try new models or swap between vendors by mostly changing a model name in code, not rewriting integrations.
Strong fit for teams that want to experiment or support user‑selectable models without building their own catalog and wiring.
Pricing
OpenRouter typically sits in front of upstream providers and charges per token through its own pricing schedule.

You pay OpenRouter for usage, and in many cases they handle the relationship with individual providers on your behalf. That simplifies billing and lets you get going quickly. But it does mean you’re adding an extra pricing layer compared to calling every vendor directly. Discounts or BYOK setups may depend on their current offering.
Routing and failover
The core benefit is access and not a full blown policy engine. You can choose between models and sometimes use their features to route by model name or provider. Although, you shouldn’t expect a deeply configurable routing layer with per-workflow policies and rich health-based routing built in.
Easiest way to think of it is “one API, many models” instead of a customizable router that encodes all your traffic rules.
Developer experience
This is where OpenRouter tends to shine. You get an OpenAI-style API, example code in multiple languages, and even the ability to plug models into existing OpenAI-compatible SDKs with minimal changes.
For teams trying to prototype or add “use different models” features fast, that ease of integration and the simple mental model are a big draw. You trade some deep control for speed and simplicity.
Governance and compliance
Since OpenRouter is a hosted service, governance and compliance questions revolve around how comfortable you are with sending traffic through a third-party gateway. You don’t have to run or patch anything yourself, but keep in mind you don’t control where every part of the stack runs.
If your team has strict data-residency or regulatory constraints, that can be a deciding factor. Some will accept it for speed. Others will need more explicit residency, policy, and audit guarantees or will prefer a self‑hosted or hybrid approach.
Use cases
OpenRouter lines up well with:
Product teams that want to offer multiple model choices quickly (e.g., “use GPT today, switch to X tomorrow”) without maintaining many separate integrations.
Startups and smaller teams that value a fast path to “try lots of models behind one API” over deeply customized routing and governance.
Internal tools and prototypes where the priority is flexibility and model coverage rather than strict control over deployment and compliance.
After understanding a bit about OpenRouter, let’s take a look at LiteLLM now.
What Is LiteLLM?

LiteLLM is an open-source abstraction layer that lets you talk to many different LLM providers through a single, unified interface that you run yourself.
Rather than relying on a hosted gateway, you deploy LiteLLM in your own environment and configure it to talk to OpenAI, Anthropic, self-hosted models, and others. This is all while your applications call LiteLLM as if it were a single API.
Think of it as “roll‑your‑own gateway,” with more control but also more operational responsibility.
Provider and model coverage
LiteLLM’s coverage is as broad as the providers you configure.
It ships with adapters for the major commercial APIs and can be extended to speak to additional endpoints, including internal or self‑hosted models. Because you own the configuration, you decide which models are exposed, how they’re named, and how they’re grouped or aliased. Useful if you want tight control over what ends up in production.
Pricing
The core LiteLLM project is free to use under its open‑source license. You don’t pay LiteLLM per token. Instead, you pay your cloud bills and whatever each upstream provider charges. That gives you direct access to provider pricing, discounts, and BYOK setups.

However, it also means you’re responsible for running, scaling, and securing the gateway layer itself.
Routing and failover
Out of the box, LiteLLM focuses on standardizing calls and making it easy to switch between models or providers, rather than on complex dynamic routing.
You can point different routes or environments at different models, and you can build simple failover or routing logic on top. But note that you’re generally expected to own the design of any rich routing behavior (like per‑workflow rules) in your code or as extra configuration.
Developer experience
For developers, LiteLLM feels like a thin, pragmatic layer: one client, many backends. Because it’s compatible with common patterns (and often mimics the OpenAI API shape), it slots into existing code with relatively small changes.
The flip side is that you need some platform or DevOps maturity to deploy and observe it properly. It’s friendlier to teams that are already comfortable running internal services than to small teams that want a purely hosted option.
Governance and compliance
Governance is where LiteLLM leans into its self-hosted nature. Since you decide where it runs, how it’s networked, and which credentials it holds, you can align it with your existing security, VPC, and compliance story. That’s attractive for enterprises with strict data‑residency or regulatory requirements.
The trade-off is you’re responsible for building and enforcing any fine-grained policies (think per-team budgets and audit logging) on top of LiteLLM instead of getting them pre-packaged.
Use cases
LiteLLM tends to fit best when:
You want a unified LLM API but insist on running the gateway in your own cloud or Kubernetes clusters
Your platform team is comfortable owning reliability, scaling, and observability for another critical internal service
You want flexibility to plug in both major providers and self‑hosted models under one abstraction, and you’re willing to implement your own routing and governance on top
Another alternative: managed gateway with self-hosted-grade governance
OpenRouter and LiteLLM sit at opposite ends of the spectrum. One gives you a hosted “one API, many models” experience. The other gives you an open‑source abstraction you run yourself.
Orq.ai’s router aims to cover the middle ground teams that we always hear teams ask for: a managed AI gateway that still behaves like something you could have built in-house. It exposes an OpenAI‑compatible endpoint with access to hundreds of models from dozens of providers, but adds explicit routing policies, cost controls, and governance features you’d normally expect from a self‑hosted control plane.
On the access side, it gives you OpenRouter-style simplicity. One key and one base URL to reach 400+ models across 30+ providers, including major commercial APIs and open-source deployments. On the control side, it adds the knobs that LiteLLM users tend to build themselves, such as:
BYOK support
EU-hosted gateways for data residency
Per-team and per-project virtual keys
The option to run the gateway inside your own VPC when you need stricter isolation
As Orq.ai router is part of a broader platform, you also get built-in observability and evaluation instead of wiring those in separately. Every request is traced with model, route, latency, tokens and cost.
Those same traces can feed evals and experiments, and if you need more than a gateway later, the router plugs into Orq.ai’s prompt management, knowledge base, and agent runtime rather than becoming another silo.

In practice, teams tend to reach different conclusions depending on their constraints:
OpenRouter is a better fit when you want a quick, fully hosted way to try many models from a single API, don’t need deep governance, and are comfortable with a third‑party on the critical path.
LiteLLM is a better fit when you want to own the gateway entirely, are happy to run it in your own infra, and have the platform capacity to build your own routing and policy layer on top.
Orq.ai’s Router is a better fit when you want hosted simplicity plus enterprise‑grade control: multi‑provider routing, BYOK and data residency, budgets and model allowlists, and integrated observability, all without building and maintaining your own gateway stack.
OpenRouter vs LiteLLM decision framework
By this point, you’ve probably realized that the one with more models isn’t necessarily better.
The right thing to focus on is which one matches your team’s constraints and what you’re willing to own yourself.
Walk through these axes to help decide:
Data residency
Operational capacity
Governance needs
How critical the LLM layer is to your product
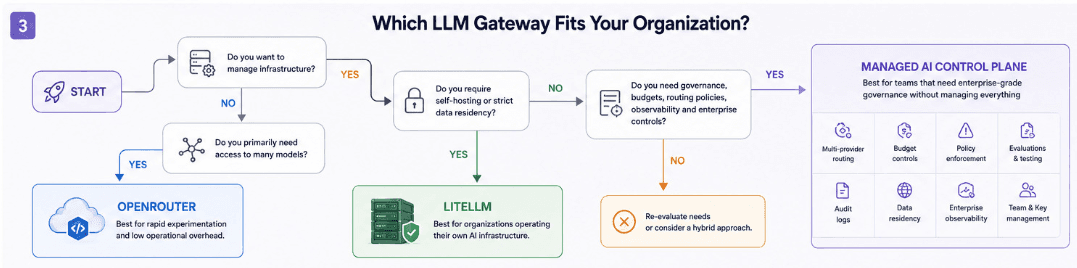
Start with where your traffic is allowed to go. If prompt data needs to stay inside your own infrastructure (such as banking or healthcare), that pushes you toward a self-hosted gateway like LiteLLM or a managed option that can run entirely in your VPC. If you can accept a cloud middleman but want to minimize internal ops, OpenRouter’s “zero-ops, one key, many models” could certainly be an option to consider.
Next, be honest about ops and ownership. If your platform team is small, you don’t have SRE capacity for another always‑on internal service, and your immediate need is to experiment across models, OpenRouter’s managed gateway is likely the lower‑risk start.
If you already run internal gateways and proxies, are comfortable with Docker/Kubernetes, and see the LLM layer as critical infra, LiteLLM’s self‑hosted proxy gives you more control in exchange for running it yourself.
Then consider governance and visibility. If you mainly want unified access and simple cost visibility, either tool can work with some custom wiring. But if you need per‑team budgets, model allowlists, detailed audit logs, and route‑level metrics without building your own control plane, neither OpenRouter nor LiteLLM gives you everything out of the box.
You’ll either add on extra systems or look at a managed gateway that emphasizes governance and tracing as first‑class features.
A practical rule of thumb that shows up across multiple comparisons is:
Choose OpenRouter if you want managed, low‑friction access to many models and are okay with a hosted dependency in your request path.
Choose LiteLLM if self‑hosting and data control are non‑negotiable, and you’re ready to treat the gateway as a piece of internal infrastructure you operate.
Consider a managed control plane like Orq.ai if multiple teams rely on LLMs, governance and observability are now explicit requirements, and you’d rather buy routing, budgets, and auditability than staff an internal platform to build them.
Make the gateway fit your stack, not the other way around
By the time you’re comparing OpenRouter and LiteLLM, you’re not asking “do we need a gateway?” so much as “who should own this layer and how much control do we need?”
When the LLM layer becomes shared infrastructure like multiple teams depending on the same routes and finance pushing for clear cost breakdowns, it can be worth reaching for something more opinionated.
If you want OpenRouter‑level simplicity with LiteLLM‑level governance, this is where a managed control plane like Orq.ai’s Router fits: one API across hundreds of models, with routing, budgets, and observability built in.
Want OpenRouter‑style simplicity with LiteLLM‑style governance? See how Orq.ai compares by booking a demo and pressure‑testing it against your actual stack and constraints.
FAQs
Is OpenRouter or LiteLLM better for production LLM workloads?
It depends on your constraints: OpenRouter is better if you want a fully managed gateway with minimal ops and quick access to many models. LiteLLM is better if you want to self‑host the gateway, keep traffic in your own infra, and are willing to operate it like core platform infrastructure.
Which has more models, OpenRouter or LiteLLM?
OpenRouter exposes a large hosted catalog of models out of the box, so you get breadth immediately by just signing up and calling their API. LiteLLM can match or exceed that breadth, but only if you actually connect and configure those providers yourself.
Can I self‑host LiteLLM but not OpenRouter?
Yes. LiteLLM is designed to be self‑hosted as a proxy you run in your own environment. OpenRouter is a managed SaaS gateway, so you can’t run it yourself; all traffic goes through their infrastructure.
What's the pricing difference between OpenRouter and LiteLLM?
OpenRouter typically charges per token with a platform fee on top of underlying model costs, which makes it cheap to start but more noticeable at high volume. LiteLLM itself is open source, so you pay your infra and provider bills directly, plus any enterprise features if you buy them.
Can I use OpenRouter and LiteLLM together?
Yes. You can treat OpenRouter as just another upstream provider behind a LiteLLM deployment. That lets you keep routing and policies in your environment while still calling models via OpenRouter when it’s convenient.
Are there better alternatives to both?
If you mainly want a simple gateway or a library, OpenRouter and LiteLLM cover most needs. If you also need built‑in routing policies, budgets, observability, and governance, a more opinionated managed control plane (like Orq’s router) can be a better fit.

Sohrab Hosseini
Co-founder (Orq.ai)
About
Sohrab is one of the two co-founders at Orq.ai. Before founding Orq.ai, Sohrab led and grew different SaaS companies as COO/CTO and as a McKinsey associate.
