

Sovereign AI Gateway
The AI gateway for every LLM
Route all your AI traffic through a single, production-ready gateway. Govern and observe every request, all inside Europe.
Live in 2 minutes • $1 free credit, no card
Secure by design
European sovereign
Full observability
Trusted by teams shipping AI at scale


Providers
Models
Uptime
Get started
How it works
1. Sign up
Create your Orq account and get instant access to the AI Gateway. Start with $1 of free credit - no card required.
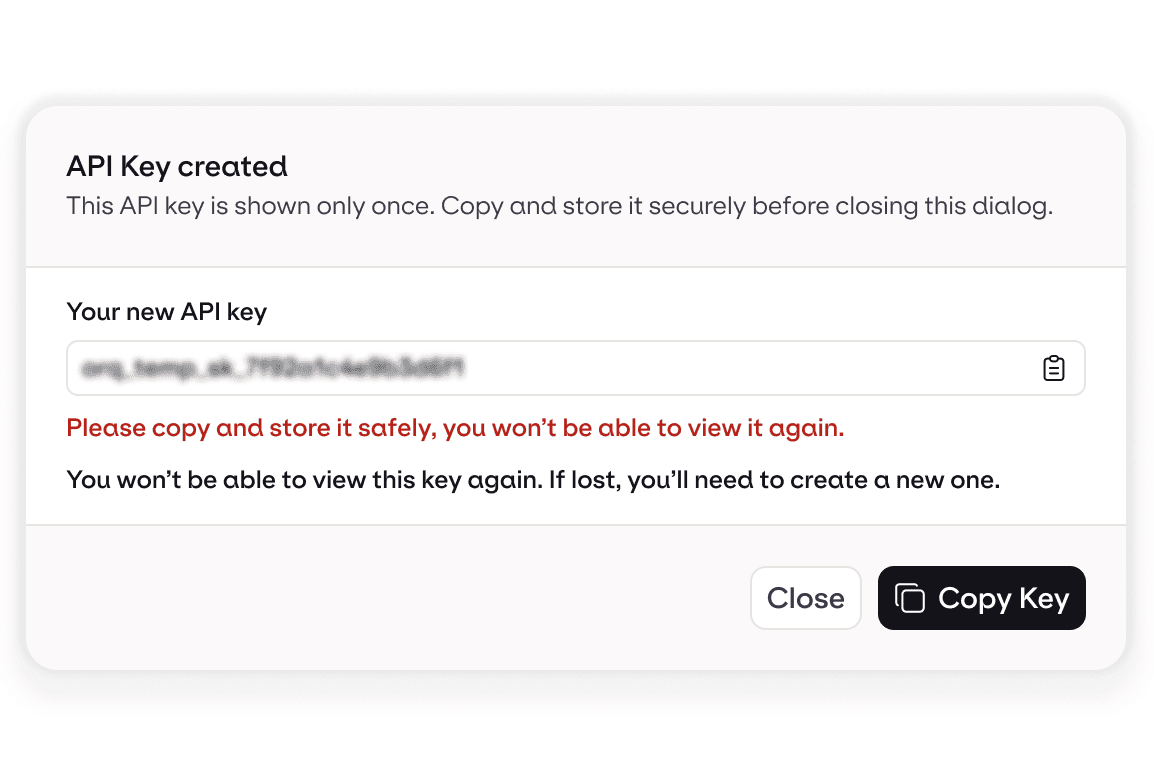
2. Grab your API key
One key, one OpenAI-compatible endpoint. Drop it into whatever you're already building - change a single line of base-URL code and you're live.
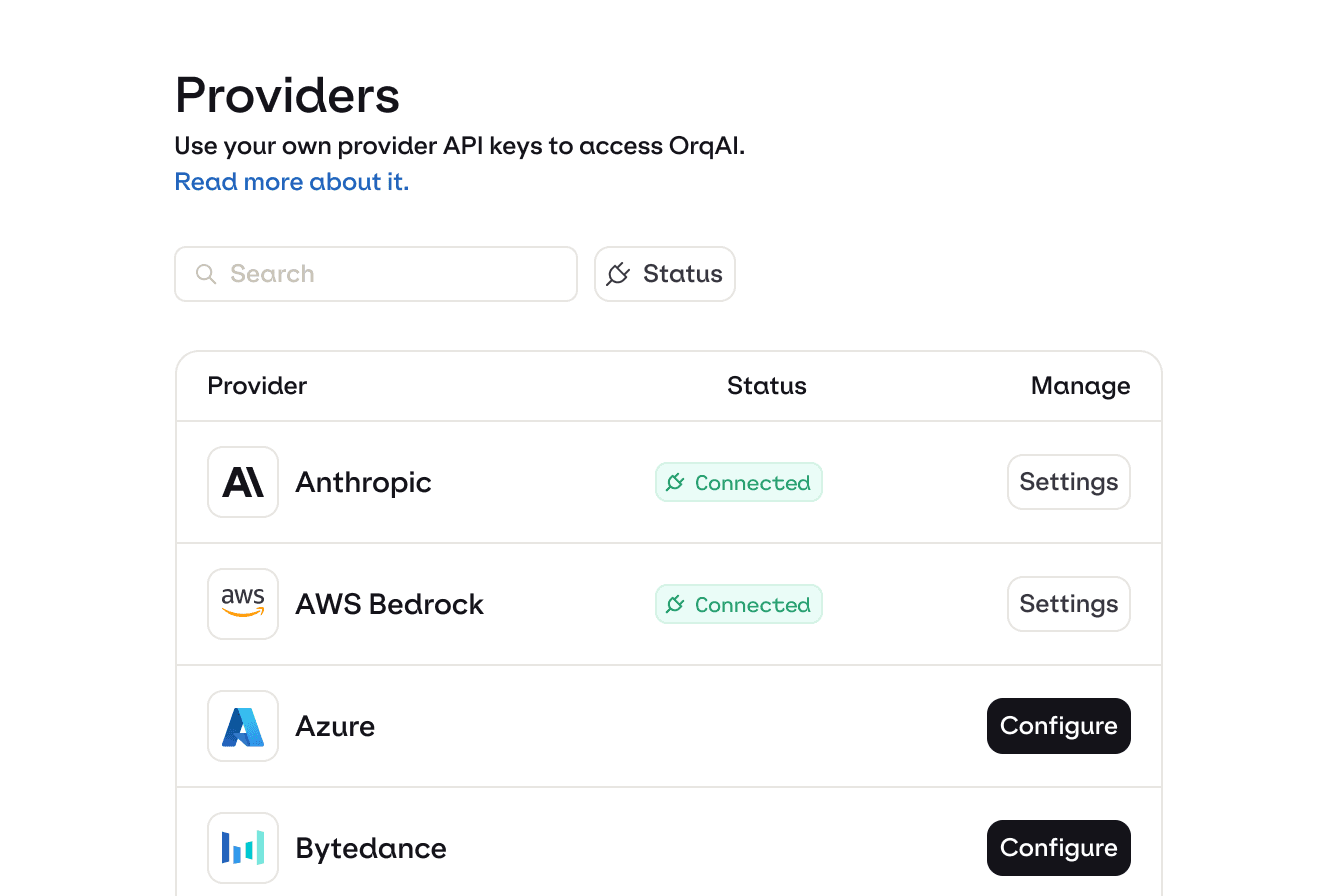
3. Start routing
Send your first request. Switch models with a string change, or let Auto Router choose. Layer on fallbacks, policies, and observability whenever you're ready.
Auto Router
Stop paying frontier prices for simple prompts
Auto Router reads every request and sends it to the model that fits - cheap and fast for simple tasks, frontier-grade for the hard ones. Up to 50% lower costs, ~98% of the quality.

You set the dial
Tune toward maximum savings or maximum quality any time, set routing policies and guardrails
Routing + observability
See, route, and control every request from one place
Most AI gateways just pass keys. Most observability tools just watch. Most teams bolt on policies. Orq does all three, at the gateway level.
Zero maintenance
Fully managed. Nothing to patch, nothing to maintain.
One control plane
Route traffic and read the traces in a single dashboard, with cost attribution by user or team.
Policies that enforce themselves
Routing rules, PII redaction, and automatic failovers, applied to every request that matches.

Features
Everything you need in an AI gateway.






The AI Gateway is part of the Orq platform
When you're ready for evals, agents, and full AI governance, it's all here.
For platform and enterprise teams
Ready for the whole organization, not just one developer
When AI goes from a side project to production across teams, you need control. Orq brings it into one place.
Testimonials
Teams that run on our AI gateway
We chose to work with Orq.ai to replace our internal setup with a production-ready AI Gateway that meets our governance, scalability, and cost-monitoring requirements.

Benjamin Kleppe,
GenAI Lead at bunq
Connecting to Orq.ai’s platform means we no longer need to revise our own code. The platform provides full control over the functionality of the models, saving considerable time and manual adjustments.

Thomas Goijarts,
Founder, Caro health
