
LLM Vendor Lock-In: What It Costs and How to Avoid It [2026]
LLM vendor lock-in costs enterprises millions in migration, blocked innovation, and outage exposure. Learn what triggers lock-in and how to avoid it.

Sohrab Hosseini
Co-founder (Orq.ai)
![LLM Vendor Lock-In: What It Costs and How to Avoid It [2026]](https://framerusercontent.com/images/s0FS6nTYtWF6RPyCG0oZp4LCJM.webp?width=2400&height=1200)
Bring LLM-powered apps from prototype to production
Discover a collaborative platform where teams work side-by-side to deliver LLM apps safely.







A deliberate platform decision isn’t what causes vendor lock-in for most teams.
It’s speed.
A team picks one model provider. They add a few provider-specific features because they work well at the time. The first version ships faster. The architecture feels simple.
Then? The system grows.
More workflows depend on the same provider. Internal tools and customer-facing features start sharing the same model layer. Prompts are a lot harder to move since they were shaped around one model’s quirks. Evaluation data sits in one platform. Any fine-tuned models can’t be exported. The team wants to test alternatives. But switching now means touching application code and evals.
That’s what vendor lock-in looks like.
And it matters even more in 2026 because production AI stacks are becoming multi-model by default. Teams are always telling us that they want the freedom to use frontier models for complex reasoning and lower-cost models for simple tasks.
That flexibility only exists if the architecture supports it. 94% of IT leaders fear vendor lock-in as AI becomes more deeply embedded in their enterprise infrastructure.
This guide will look at what LLM vendor lock-in is, where it hides in the AI stack, and what it can cost.
What is LLM vendor lock-in?
LLM vendor lock-in is when an enterprise is so reliant on a certain LLM that switching to a cheaper or more advanced model becomes a huge obstacle from a financial standpoint.
Code is written around a specific SDK. Prompts are tuned for one model’s behavior. Tool-calling formats depend on one vendor’s conventions. Logs, evaluations, and cost reports live inside one platform. Fine-tuned models or embeddings may not move cleanly to another environment.
Over time, the provider becomes more than a model supplier. It becomes part of the application architecture.
And when the team finally needs to change direction they’ve already fallen too deep into the pit. A better model might be available or costs have become too high. But moving away now requires more than just changing an endpoint. It could involve:
Rewriting integrations
Retesting prompts
Rebuilding evals
Migrating data
Retraining teams
Keep in mind that LLM lock-in can be technical, operational, or regulatory. Sometimes it appears in code. Sometimes it appears in procurement terms. Sometimes it appears in workflows that only one vendor can support.
The key issue is loss of flexibility. A locked-in team cannot easily route around provider problems, compare alternatives or choose different models for different tasks. Every change becomes a project.
Why LLM lock-in happens
As we hinted at before, speed is the main culprit as to why most teams end up with LLM lock-in.
They prioritize being faster and ignore portability.
That trade-off makes sense at the beginning. A direct provider integration is fast to ship. The SDK works. The docs are clear. The first model performs well enough. For a prototype, there may be no reason to add an abstraction layer, routing logic or multi-provider testing.
The problem starts when that prototype becomes infrastructure.
Provider-specific APIs and SDKs
Teams always start by directly integrating with one provider’s API or SDK. They end up with an early dependency on the provider’s authentication and request format.
Those differences do seem small at first. But once they get embedded across several services, switching providers becomes more than a simple endpoint change. Engineers have to rewrite request handling and retest tool calls.
Prompts tuned to one model
Prompts aren’t always portable.
A prompt that works well with one model might end up producing weaker or less reliable answers with another. We always find that teams tune instructions around a provider’s style and reasoning behavior.
The application looks provider-agnostic on the outside but its prompt layer has actually adapted to one model family. It creates a hidden dependency since moving to another provider would require prompt rewriting and quality review.
Fine-tuning and embedding dependencies
Fine-tuning creates stronger lock-in as the customized model typically stays inside the provider’s environment. If the weights and training data can’t be exported cleanly, you might need to retrain from scratch elsewhere.
Embedding models creates a similar issue. If a RAG system relies on one embedding model, changing that model might require rebuilding indexes and retesting retrieval quality.
An expensive and disruptive migration for large knowledge bases.
Is LLM lock-In always a problem?
It sounds like it would be on paper, but it isn’t necessarily always an issue.
It’s important to understand that some level of vendor commitment is normal in production AI. One provider might offer the best model for a specific workload. Or, better latency in a target region.
The real problem is when dependency becomes invisible. Only 11% of enterprise groups switched primary LLM vendors in 2025, suggesting both sticky platform dynamics and the risk of being trapped.
You might think that you went with a provider for performance. But then you’ve tied prompts, evals, and logs all to the same vendor.
There’s a difference between strategic commitment and unmanaged lock-in.
Strategic commitment means the team understands the trade-off. Why they went with the provider, what would be difficult to move, and what fallback options exist. The architecture still leaves room to test alternatives and route specific tasks elsewhere when needed.
Unmanaged lock-in works differently. The dependency spreads without clear ownership. Model names are hardcoded. Prompts only work with one model family. Evaluation data sits in one platform. Cost visibility depends on one vendor dashboard. Contract terms make usage hard to reduce. Nobody knows how long migration would take until a problem forces the issue.
That’s the kind of lock-in that limits control.
You don’t want to aim to avoid every provider-specific feature. That would be unrealistic and counterproductive in a lot of instances. You want to make dependencies like fine-tuning and proprietary models deliberate.
When it comes to your approach, think about these questions first:
Which parts of the system need portability?
Which provider-specific features are worth the trade-off?
Can we test another model without rewriting the application?
Can we route around outages, price changes or regional constraints?
Do we know what migration would involve before we need it?
LLM lock-in becomes a problem when it removes optionality. If you can still monitor usage and move workflows when needed, vendor dependency is still very manageable. If every change requires a major rebuild, the architecture has become too rigid.
The real costs of LLM vendor lock-in
LLM lock-in costs more than the price of one provider’s API.
The true cost shows up when your enterprise needs to change something but can’t do it easily. A new model performs better, but testing it would require weeks of engineering work. A provider raises prices, but the product depends too heavily on its tooling. A model gets deprecated, but prompts, evals, and workflows were never designed to move. An outage hits, but there’s no tested fallback path.
That’s when lock-in becomes expensive. Fast.
Migration costs
The most obvious cost is migration.
Moving from one LLM provider to another might involve:
Rewriting integrations
Updating SDKs
Changing request and response handling
Retesting tool calls
Rebuilding evals
Validating outputs across every affected workflow
The work rarely stays contained to one engineering ticket.
A customer-support assistant might need prompt changes and RAG testing. An internal agent might need tool-calling behavior retested from end-to-end. A fine-tuned model might need to be rebuilt entirely with a new provider.
The deeper the dependency, the more migration looks like a build.
Higher operating costs
Lock-in can also make LLM usage more expensive over time.
If every workflow depends on one provider, then you have less room to route simple tasks to cheaper models or shift traffic when pricing changes. Cost optimization becomes limited to whatever that provider supports.
But why does that matter?
Because not every request needs the same model. Classification and simple rewriting don’t need frontier-level reasoning. If the architecture can’t route by task complexity, you might overpay for workloads that can run well on lower-cost models.
Lock-in turns model choice into a fixed cost structure. 80% of enterprises see their AI costs exceed initial forecasts. Without routing flexibility, there's no easy way to optimize spend when it happens.
Outage and availability risk
A single-provider architecture creates reliability exposure.
If that provider has an outage or model incident, every dependent workflow is affected. You won’t have a tested fallback or easy way to shift traffic elsewhere.
That can be acceptable for low-risk tools. But for customer-facing products and support agents, it affects the entire enterprise.
Even though multi-provider architecture doesn’t remove outages, it gives you options when one provider fails.
Red flags you're already locked in
Signs of LLM vendor lock-in usually appear before a full migration problem. Watch for these warning signals:
Your prompts only work well with one model family: The same instructions produce weaker, less structured or less reliable outputs when tested elsewhere.
Tool calling depends on one vendor’s format: Function schemas, JSON handling, streaming behavior or tool execution logic would need major changes to move.
You don’t have a tested fallback provider: If the primary provider goes down, rate-limits traffic or deprecates a model, there’s no reliable backup route.
Usage data lives only in the provider dashboard: Cost, latency, token usage and error data can’t be compared easily across vendors or workflows.
Evals are tied to one platform: Test cases, scoring logic or historical results aren’t portable enough to benchmark another model confidently.
Fine-tuned models cannot be exported or recreated easily: The team depends on custom model behavior that only exists inside one provider’s environment.
Security and compliance approvals cover only one provider: Adding another vendor would require a long legal or procurement review from scratch.
One or two red flags may be manageable.
The risk becomes more serious when several appear together across code, prompts, and observability.
How to avoid LLM lock-in
Avoiding LLM lock-in doesn’t mean you have to be neutral on every provider decision.
Instead, you want to design your AI stack so that model choices are flexible when costs and compliance needs change.
1. Keep prompts outside the model provider
Try to keep prompts versioned and managed independently from any single vendor. Migration becomes a lot harder if your prompts all live inside one provider’s tooling.
A reliable prompt workflow should track prompt versions and eval results across providers. That way, you’ll see if a prompt works broadly or only performs well with one model family.
2. Build portable evals from the start
Evals are one of the best defenses against lock-in. They let you compare models using real tasks and quality expectations instead of vendor demos or generic benchmarks.
The key is to keep those evals outside any single provider’s platform. Your test cases and historical results should be reusable across different models.
Otherwise, the evaluation process itself becomes another dependency.
3. Avoid hardcoding model choices into workflows
Model selection should be configurable. Hardcoded model names and one-off routing logic make it tough to switch later.
A better pattern is to map tasks to model policies.
For example: simple classification uses a low-cost route, sensitive workflows use approved regional providers, and complex reasoning uses stronger models with tested fallbacks. The application calls the task route and not a fixed vendor.
“If switching models means rewriting your prompts, evals, and workflows, the architecture was already too fragile. You want to model choice to be a configuration change, not a rebuild.” - Sohrab Hosseini, Orq.ai co-founder
How an AI gateway reduces LLM vendor lock-in
An AI gateway reduces LLM vendor lock-in by separating the application from the model provider.
Without a gateway, the application talks directly to one vendor. Provider-specific SDKs, credentials, and logs start to spread through the codebase. The longer that continues, the harder it becomes to switch models or add another provider.
With a gateway, the application talks to one abstraction layer. The gateway manages the provider connections behind it.
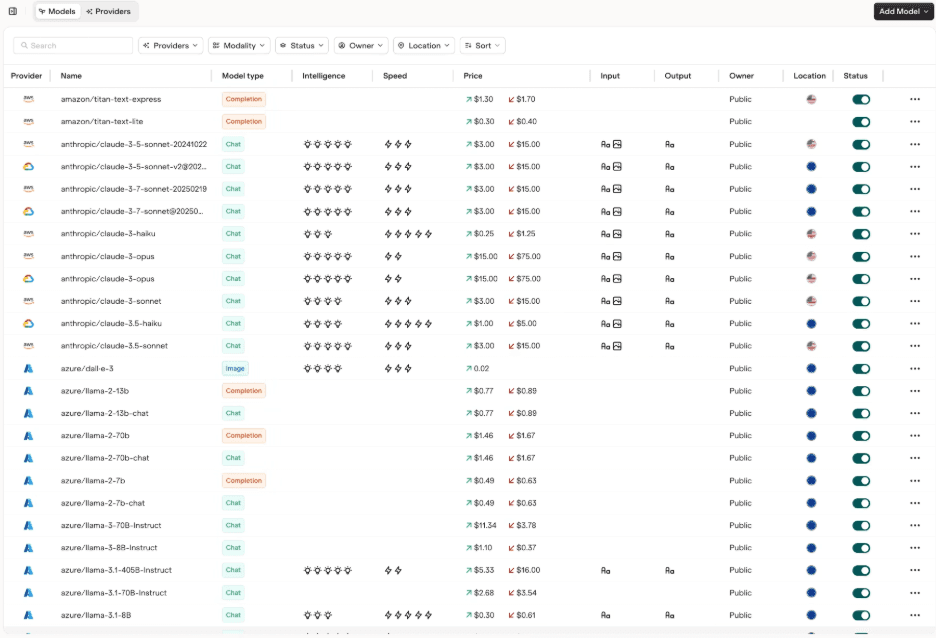
One API for multiple providers: A gateway gives applications one interface for accessing multiple models, so teams can add or test providers without rewriting application logic.
Configurable routing instead of hardcoded models: Requests can be routed by task or risk level instead of being tied to fixed model names in the codebase.
Tested fallback paths: Define and validate backup models before outages, rate limits or model deprecations force an urgent migration.
Portable observability: Gateway-level traces give teams a shared view of prompts and route decisions across providers.
Centralized budgets and usage controls: Spend can be tracked and managed by provider or workflow so cost optimization is easier without a full migration.
Governance that travels across providers: Approved model lists and audit logs can stay consistent as new providers are added.
Vendor evaluation checklist: lock-in risk before you commit
Vendor lock-in is easier to prevent before the contract is signed.
Once a provider is embedded in code and prompts, the cost of leaving means that it’s a decision that needs to be thought through.
Use these questions to assess lock-in risk before committing to an LLM provider or AI infrastructure vendor.
Question | Why it matters | What to look for |
Does the vendor offer OpenAI-compatible APIs? | API compatibility makes it easier to switch providers, reuse existing SDK patterns and reduce provider-specific code. | Support for standard request formats, chat completions, streaming, tool calls and clear migration documentation. |
Can you bring your own keys? | BYOK lets you keep direct relationships with model providers instead of routing all usage through one vendor’s billing structure. | Support for your own provider accounts, no forced markup, clear credential handling and control over which models are enabled. |
What are the data export and deletion terms? | Prompts, outputs, logs, files, evals and fine-tuning data can become hard to move if export rights are unclear. | Clear export formats, deletion timelines, retention controls, audit logs and documented ownership of customer data. |
Are there fine-tuning portability options? | Fine-tuned models can create deep dependency if the trained behavior cannot be reproduced elsewhere. | Access to training data, configuration details, evaluation results, export options where possible and a documented retraining path. |
Does the vendor support self-hosting or in-VPC deployment? | Deployment flexibility matters for sensitive workloads, regulated sectors and organizations with strict network controls. | Managed cloud, private cloud, self-hosted, in-VPC, regional deployment or hybrid options. |
Are pricing tiers transparent and stable? | Unclear pricing makes future operating costs harder to predict and can weaken negotiating power later. | Published pricing, predictable usage metrics, clear overage terms, no hidden provider markup and advance notice for changes. |
Is there a documented multi-provider integration path? | A vendor that only supports one model ecosystem may limit future model choice. | Support for multiple commercial providers, open-source models, self-hosted models, fallback routes and provider comparison workflows. |
What is the vendor’s compliance posture? | Security and compliance approvals often determine whether a provider can support production or regulated use cases. | SOC 2, GDPR support, EU AI Act readiness, HIPAA where relevant, subprocessors, data residency controls and access controls. |
What does the contract say about price changes, termination and data ownership? | Commercial terms can create lock-in even when the technical architecture stays portable. | Fair termination rights, clear data ownership, export rights, deletion commitments, price-change notice periods and limits on forced commitments. |
The best vendors make exit paths clear even when they expect customers to stay. That is the difference between a strategic platform choice and a dependency that becomes expensive to unwind later.
How Orq.ai helps reduce LLM lock-in in production AI systems
Most gateway solutions stop at routing. They give you a unified API and call it done. But the underlying lock-in problem is still there. Prompts are still tuned to one model. Evals still live in a provider dashboard. Cost data still comes from one vendor's billing page.
You've added a routing layer without solving the portability problem.
Orq.ai sits between your application and 400+ models across 20+ providers through a single OpenAI-compatible API. With BYOK (bring your own keys), you keep direct relationships with your providers. No markup, no forced consolidation through one vendor's billing structure.
What makes it genuinely different is the abstraction layer goes all the way down. Prompts live in a central, versioned library outside any one provider.
Evals run against your own datasets and scoring logic, portable across models. The knowledge base and RAG pipeline sit in the platform, not inside a vendor environment.
Keep model choice in your control
Lock‑in rarely shows up as one big mistake. It creeps in through small, reasonable decisions like “we’ll just use this SDK for now” and “we’ll tune this prompt for that one model.” Until it's too late to turn back because of how risky and expensive it would be to change.
You don’t need to avoid every vendor-specific feature. You do need to know where your dependencies are, and keep the door open to try something better when it appears. That’s why it pays to keep prompts, evals, and usage data in your own layer.
This is the problem Orq.ai is built around. We give teams a single place to design prompts and see how models behave in production so choosing a different model is a configuration change, not a rewrite.
Ready to keep model choice as a configuration and not a rebuild? Book a demo and we’ll map out what that looks like for your stack.

Sohrab Hosseini
Co-founder (Orq.ai)
About
Sohrab is one of the two co-founders at Orq.ai. Before founding Orq.ai, Sohrab led and grew different SaaS companies as COO/CTO and as a McKinsey associate.
